克雷西 发自 凹非寺
量子位 | 公众号 QbitAI
不用H100,三台苹果电脑就能带动400B大模型。
背后的功臣,是GitHub上的一个开源分布式AI推理框架,已经斩获了2.5k星标。
利用这个框架,几分钟就能用iPhone、iPad等日常设备构建出自己的AI算力集群。
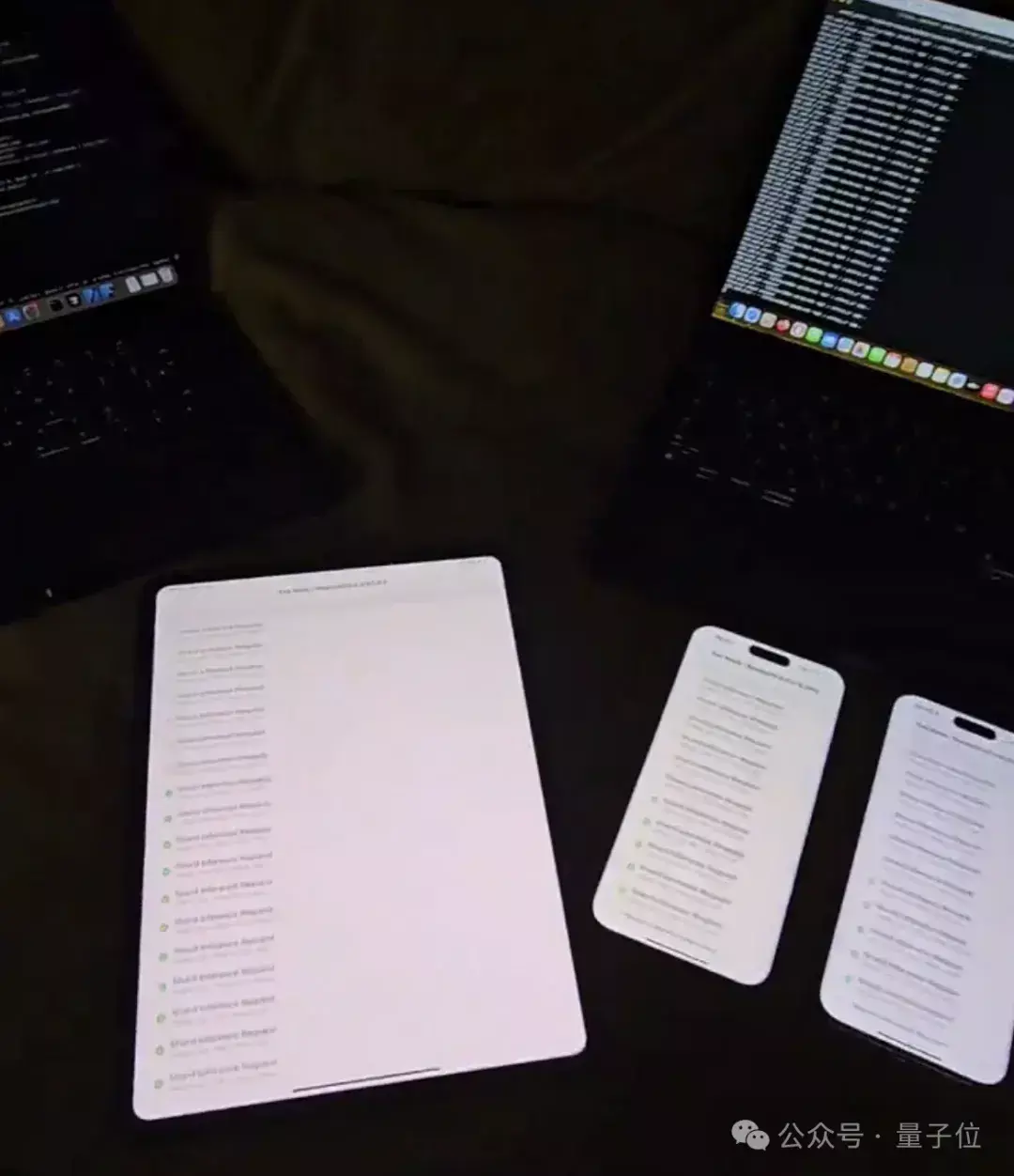
这个框架名叫exo,不同于其他的分布式推理框架,它采用了p2p的连接方式,将设备接入网络即可自动加入集群。
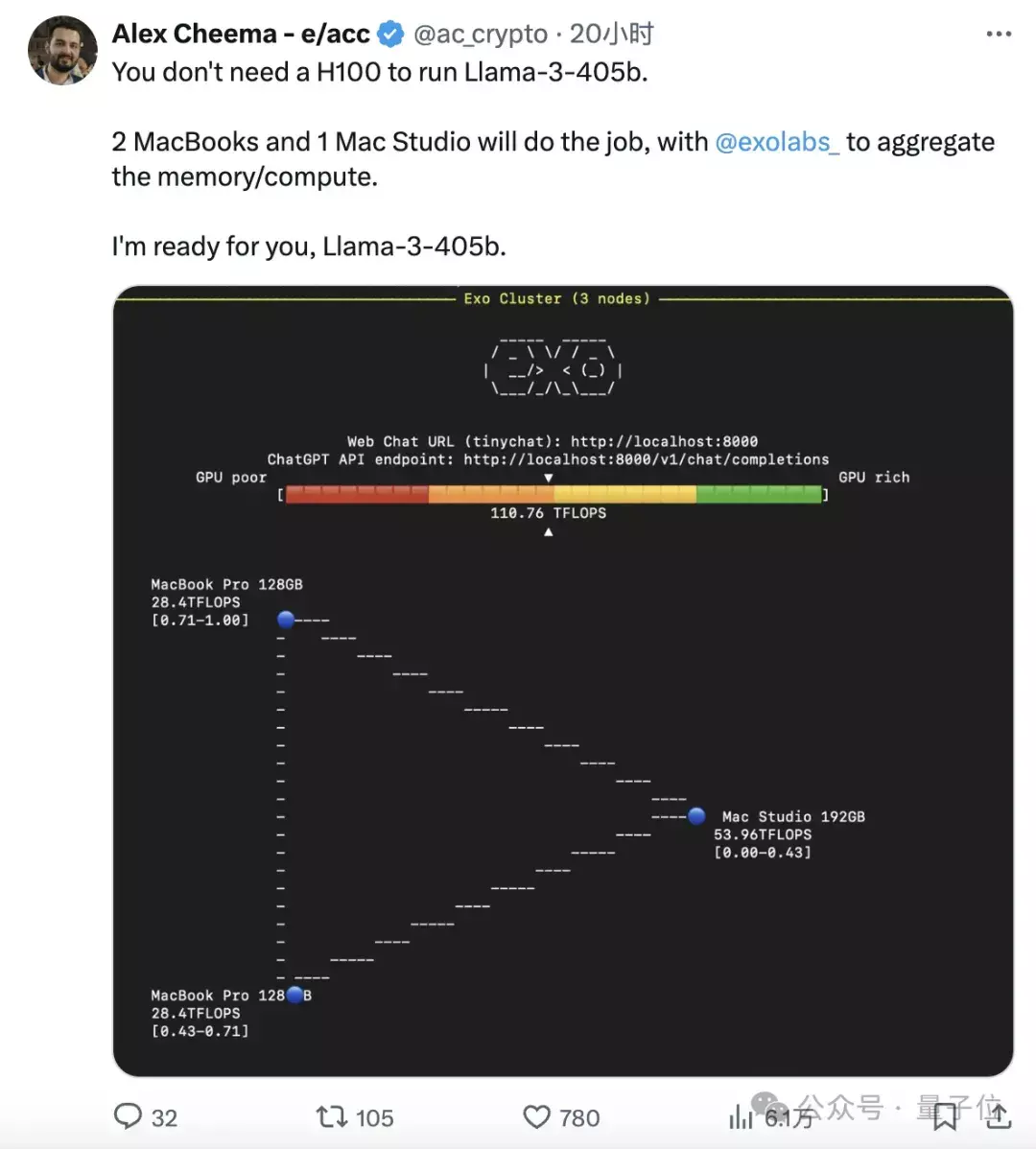
开发者使用exo框架连接了两台MacBook Pro和一台Mac Studio,运算速度达到了110TFLOPS。
同时这位开发者表示,已经准备好迎接即将到来的Llama3-405B了。
exo官方也放话称,将在第一时间(day 0)提供对Llama3-405B的支持。

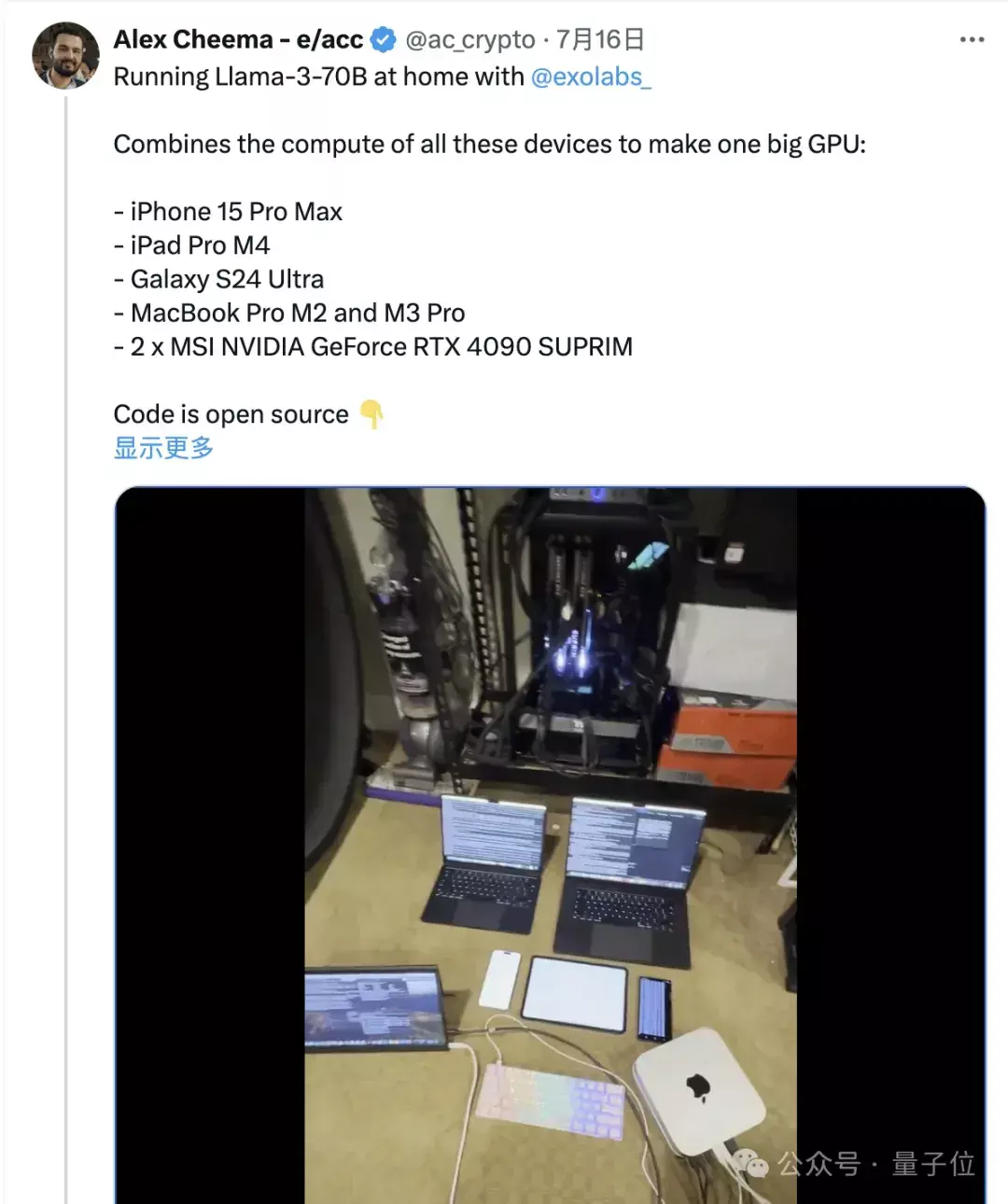
而且不只是电脑,exo可以让iPhone、iPad等设备也加入本地算力网络,甚至Apple Watch也同样能够吸纳。

随着版本的迭代,exo框架也不再是苹果限定(起初只支持MLX),有人把安卓手机和4090显卡也拉进了集群。
最快60秒完成配置
与其他分布式推理框架不同,exo不使用master-worker架构,而是点对点(p2p)地将设备进行连接。
只要设备连接到相同的局域网,就可以自动加入exo的算力网络,从而运行模型。
在对模型进行跨设备分割时,exo支持不同的分区策略,默认是环内存加权分区。
这会在环中运行推理,每个设备分别运行多个模型层,具体数量与设备内存成比例。
而且整个过程几乎无需任何手动配置,安装并启动之后系统就会自动连接局域网内运行的设备,未来还会支持蓝牙连接。
在作者的一段视频当中,只用了60秒左右就在两台新的MacBook上完成了配置。
可以看到,在60秒左右时,程序已然开始在后台运行。
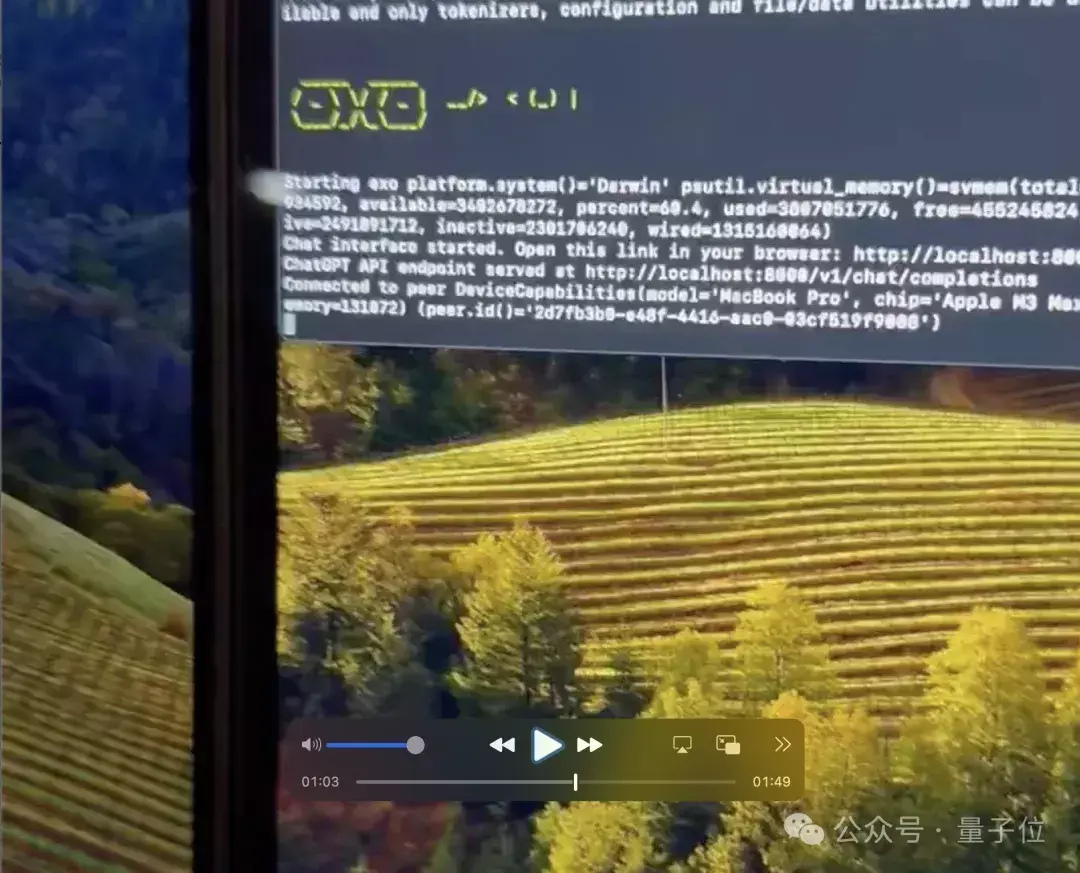
另外从上面这张图中还能看出,exo还支持tiny chat图形化界面,同时还有兼容OpenAI的API。
不过,这样的操作只能在集群中的尾节点(tail node)上实现。

目前,exo支持苹果MLX框架和开源机器学习框架tinygrad,对llama.cpp的适配工作也正在进行。
美中不足的是,由于iOS实现更新跟不上Python,导致程序出现很多问题,作者把exo的手机和iPad端进行了暂时下线,如果确实想尝试,可以给作者发邮件索取。

网友:真有那么好用?
这种利用本地设备运行大模型的方式,在HakerNews上也引发了广泛的讨论。
本地化运行的优点,一方面是隐私更有保障,另一方面是模型可以离线访问,同时还支持个性化定制。

也有人指出,利用现有设备搭建集群进行大模型运算,长期的使用成本要低于云端服务。

但针对exo这个具体的项目,也有不少人表达了心中的疑问。
首先有网友指出,现有的旧设备算力水平无法与专业的服务商之间差了数量级,如果是出于好奇玩一玩还可以,但想达到尖端性能,成本与大型平台根本无法比较。

而且还有人表示,作者演示用的设备都是高端硬件,一个32GB内存的Mac设备可能要价超过2000美元,这个价格还不如买两块3090。
他甚至认为,既然涉及到了苹果,那可以说是和“便宜”基本上不怎么沾边了。

这就引出了另一个问题——exo框架都兼容哪些设备?难道只支持苹果吗?
网友的提问则更加直接,开门见山地问支不支持树莓派。
作者回复说,理论上可以,不过还没测试,下一步会进行尝试。

除了设备自身的算力,有人还补充说,网络传输的速度瓶颈,也会限制集群的性能。
对此,框架作者亲自下场进行了解释:
exo当中需要传输的是小型激活向量,而非整个模型权重。对于Llama-3-8B模型,激活向量约为10KB;Llama-3-70B约为32KB。本地网络延迟通常很低(<5ms),不会显著影响性能。

作者表示,目前该框架已经支持tinygrad,因此虽然测试主要在Mac设备上展开,(理论上)支持能运行tinygrad的所有设备。
目前该框架仍处于实验阶段,未来的目标是把这个框架变得像Dropbox(一款网盘)一样简单。
BTW,exo官方也列出了一些目前计划解决的缺点,并进行了公开悬赏,解决这些问题的人将获得100-500美元不等的奖金。

GitHub:https://github.com/exo-explore/exo
参考链接:https://x.com/ac_crypto/status/1814912615946330473— 完 —
量子位 QbitAI · 头条号签约
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com