
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
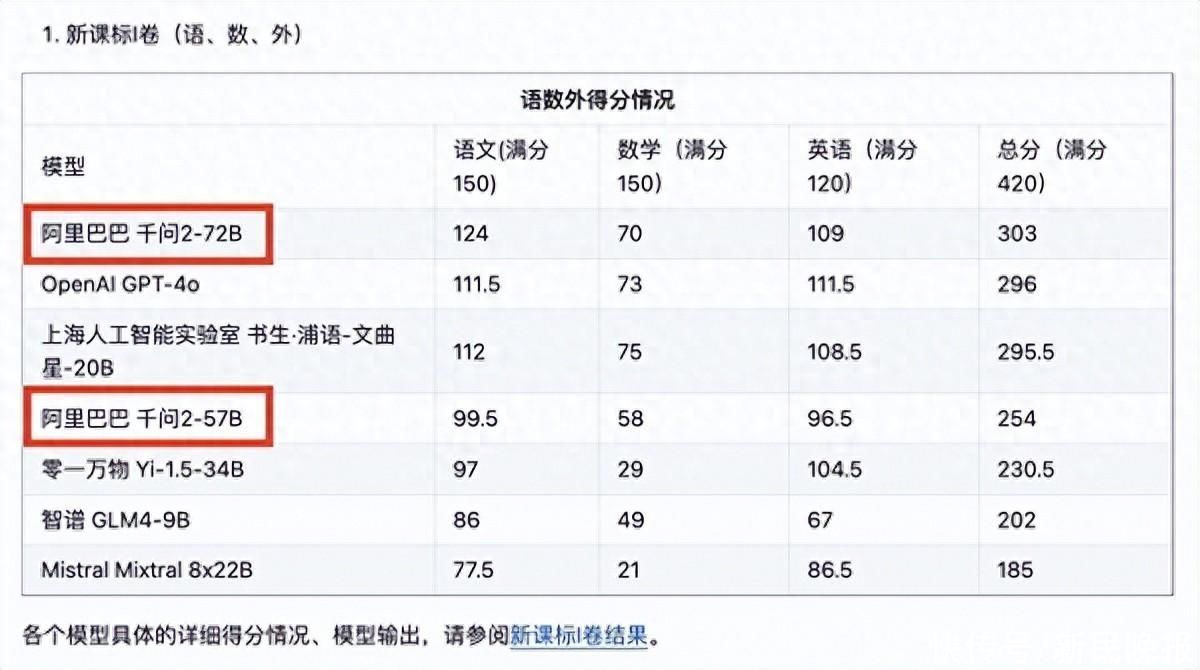
首个AI高考全卷评测结果发布,阿里通义Qwen2模型排名第一
5
0
相关文章
近七日浏览最多
最新文章
标签云
中专
高中
一心
高考
黄玲
吴家
小巷人家
北航
学霸
作弊
辅导员
清华大学
教书育人楷模
社会
农校
农业
大学
动物
植物
华南农业大学
校庆
广州
央视
澎湃
新闻
网暴
湖南省
网络暴力
林武峰
向鹏飞
被开除
考研
海马体
报考点
招考办
谷雨
教育
读书
张桂梅
山花烂漫时
高平
学历
柴进
大元
好团圆
鹏飞
凤凰男
闫妮
考试
备考
民生
江苏
教辅
金箍棒
真经
课外辅导
关关
全剧
国剧
招生
招生组
高校
录取线
复读
唐尚珺
范进中举
入学
学校
华南师范大学
宋祖儿
偷税漏税
新东方
吉林大学
土木工程
投档分数线
快递
清华
云南
录取通知书
录取分数线
哈尔滨工程大学
高考成绩
中南大学
985高校
研究生
人生
南京工业大学
明清时期
科举制度
美国
文科
本科
眼镜蛇
是真的吗
学习习惯
素质教育
衡水中学
二本
中国移动
人工智能
通信
通信技术
ai
谷歌
李世石
阿尔法狗
哈萨比斯
诺贝尔奖
alphago
科学
教授
诺贝尔物理学奖
华为
项立刚
孙凝晖
中科院
任正非
天眼查
科大讯飞
南京
联合国
中兴通讯
中国联通
中国电信
nlp
操作系统
股票
科技
万军伟
上交所
英伟达
ipad
乔布斯
苹果
网络安全
上海
app
初创公司
微软
美股
戴尔
芯片
愿景基金
孙正义
股价
软银
arm
联想
inc
山东省
济南
金融服务
金融科技
新加坡
减持
价值投资
北京商报
北京
人工智能技术
mate
花旗
e30
大数据
健身房
云计算
物联网
a股