就在刚刚,Meta 如期发布了 Llama 3.1 模型。
简单来说,最新发布的 Llama 3.1 405B 是 Meta 迄今为止最强大的模型,也是全球目前最强大的开源大模型,更是全球最强的大模型。
从今天起,不需要再争论开源大模型与闭源大模型的孰优孰劣,因为 Llama 3.1 405B 用无可辩驳的实力证明路线之争并不影响最终的技术实力。
先给大家总结一下 Llama 3.1 模型的特点:
- 包含 8B、70B 和 405B 三个尺寸,最大上下文提升到了 128K,支持多语言,代码生成性能优秀,具有复杂的推理能力和工具使用技巧
- 从基准测试结果来看,Llama 3.1 超过了 GPT-4 0125,与 GPT-4o、Claude 3.5 互有胜负
- 提供开放/免费的模型权重和代码,许可证允许用户进行微调,将模型蒸馏到其他形式,并支持在任何地方部署
- 提供 Llama Stack API,便于集成使用,支持协调多个组件,包括调用外部工具
附上模型下载地址:
https://huggingface.co/meta-llama https://llama.meta.com/
 超大杯登顶全球最强大模型,中杯大杯藏惊喜
超大杯登顶全球最强大模型,中杯大杯藏惊喜本次发布的 Llama 3.1 共有 8B、70B 和 405B 三个尺寸版本。
从基准测试结果来看,超大杯 Llama 3.1 405B 全方位耐压了 GPT-3.5 Turbo、大部分基准测试得分超过了 GPT-4 0125。
而面对 OpenAI 此前发布的最强闭源大模型 GPT-4o 和第一梯队的 Claude 3.5 Sonnet,超大杯依然有着一战之力,甚至可以仅从纸面参数上说,Llama 3.1 405B 标志着开源大模型首次追上了闭源大模型。
具体细分到基准测试结果,Llama 3.1 405B 在 NIH/Multi-needle 基准测试的得分为 98.1,虽然比不上 GPT-4o,但也表明其在处理复杂信息的能力上堪称完美。
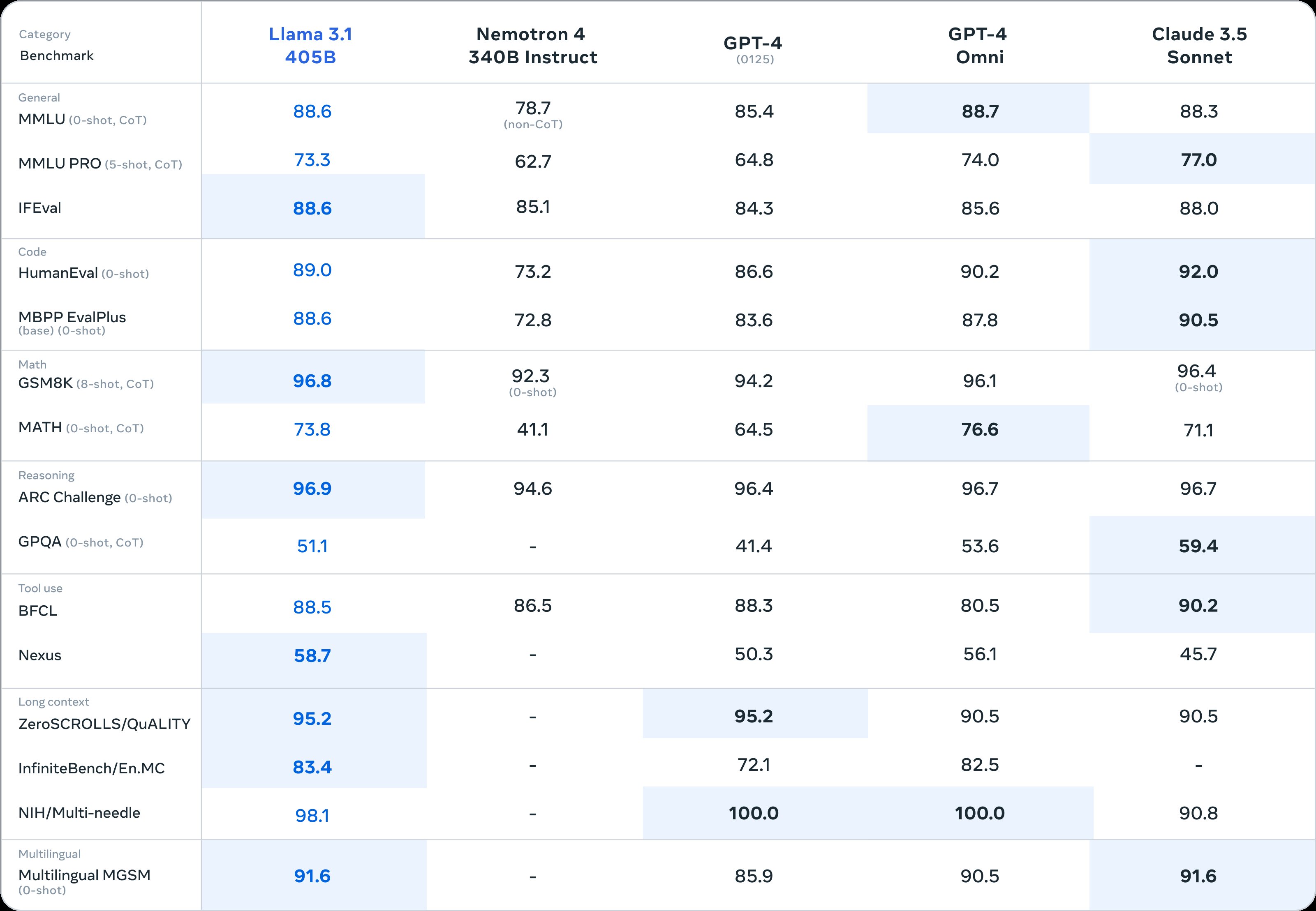
并且 Llama 3.1 405B 在 ZeroSCROLLS/QUALITY 基准测试的得分为 95.2,也意味着其具有强大整合大量文本信息的能力,这些结果表明,LLaMA3.1 405B 模型在处理长文本方面出色,对于关注 LLM 在 RAG 方面性能的 AI 应用开发者来说,可谓是相当友好。
尤为关注的是,Human-Eval 主要是负责测试模型在理解和生成代码、解决抽象逻辑能力的基准测试,而 Llama 3.1 405B 在与其他大模型的比拼中也是稍占上风。
除了主菜 Llama 3.1 405B,虽为配菜的 Llama 3.1 8B 和 Llama 3.1 70B 也上演了一出「以小胜大」的好戏。
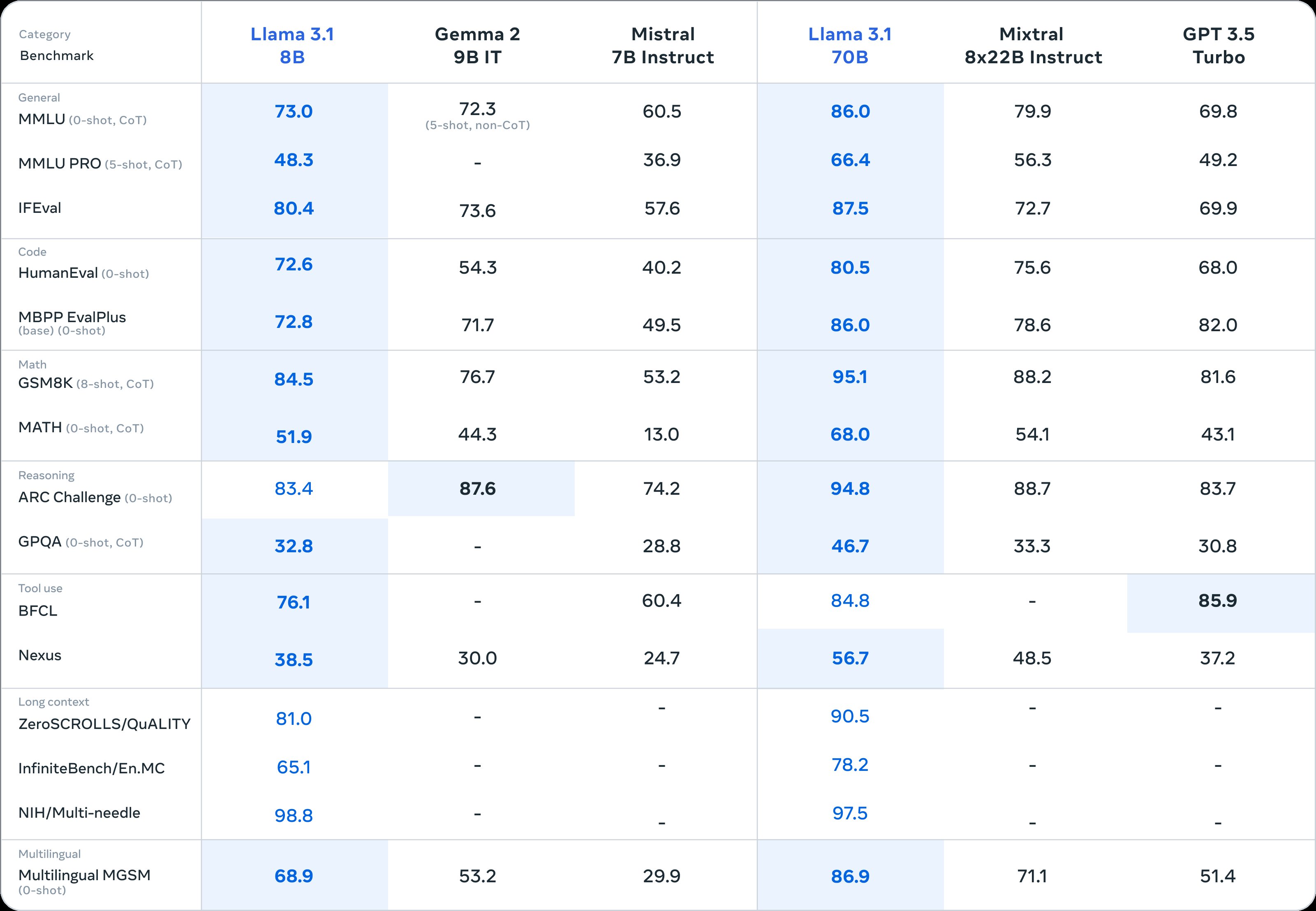
就基准测试结果来看,Llama 3.1 8B 几乎碾压了 Gemma 2 9B 1T,以及 Mistral 7B Instruct,整体性能甚至比 Llama 3 8B 都有显著提升。Llama 3.1 70B 更是能越级战胜 GPT-3.5 Turbo 以及性能表现优异的 Mixtral 8×7B 模型。
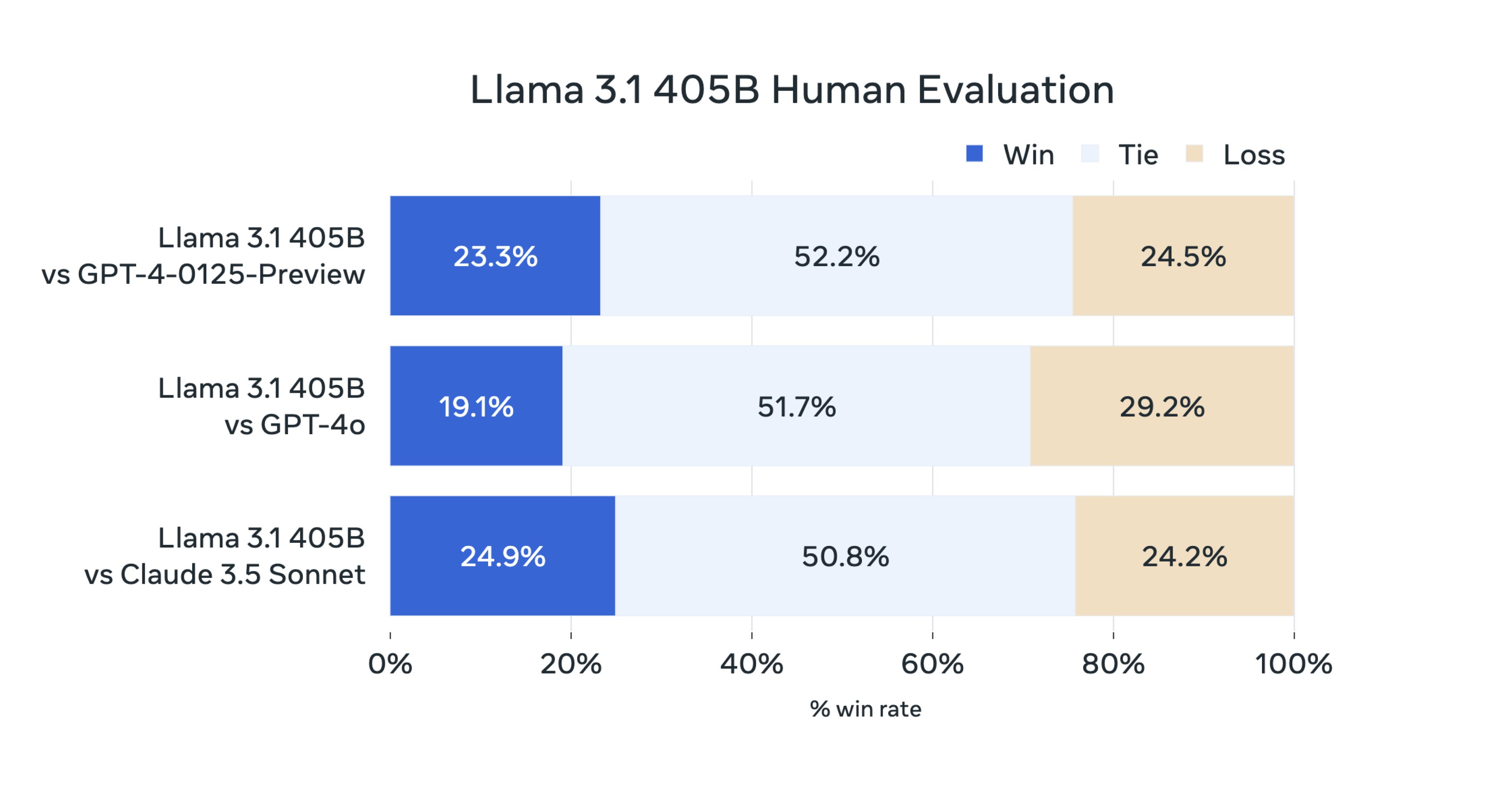
据官方介绍,在这次发布的版本中,Llama 研究团队在 150 多个涵盖多种语言的基准数据集上对模型性能进行了评估,以及团队还进行了大量的人工评估。
最终得出的结论是:
我们的旗舰模型在多种任务上与顶尖的基础模型,如 GPT-4、GPT-4o 和 Claude 3.5 Sonnet 等,具有竞争力。同时,我们的小型模型在与参数数量相近的封闭和开放模型相比时,也展现出了竞争力。
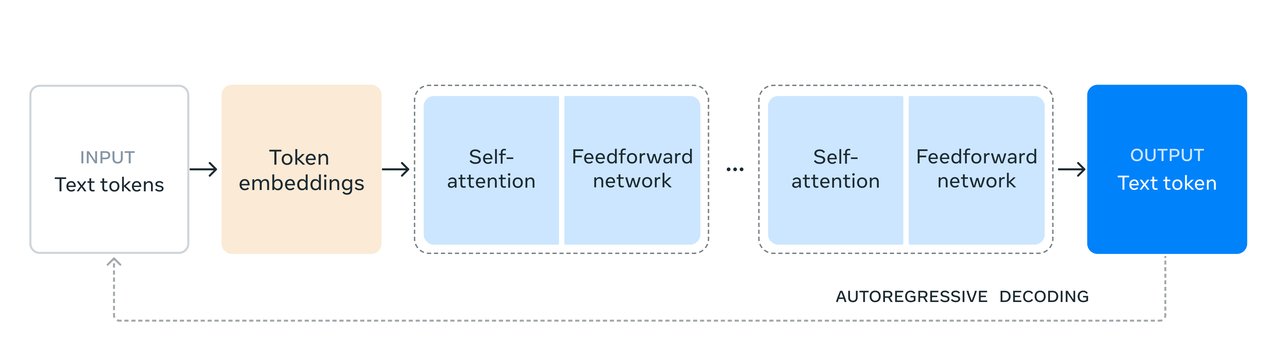
那 Llama 3.1 405B 是怎么训练的呢?
据官方博客介绍,作为 Meta 迄今为止最大的模型,Llama 3.1 405B 使用了超过 15 万亿个 token 进行训练。
为了实现这种规模的训练并在短时间内达到预期的效果,研究团队也优化了整个训练堆栈,在超过 16000 个 H100 GPU 上进行训练,这也是第一个在如此大规模上训练的 Llama 模型。
团队也在训练过程中做了一些优化,重点是保持模型开发过程的可扩展性和简单性:
- 选择了仅进行少量调整的标准解码器 Transformer 模型架构,而不是混合专家模型,以最大限度地提高训练稳定性。
- 采用了一种迭代后训练程序,每一轮都使用监督微调和直接偏好优化。这使得研究团队能够为每轮创建最高质量的合成数据,并提升每项功能的性能。
- 相较于旧版 Llama 模型,研究团队改进了用于预训练和后训练的数据数量和质量,包括为预训练数据开发更预处理和管理管道,为后训练数据开发更严格的质量保证与过滤方法。
Meta 官方表示,在 Scaling Law 的影响之下,新的旗舰模型在性能上超过了使用相同方法训练的小型模型。
研究团队还利用了 405B 参数模型来提升小型模型的训练后质量。
为了支持 405B 规模模型的大规模生产推理,研究团队将模型从 16 位(BF16)精度量化到 8 位(FP8)精度,这样做有效减少了所需的计算资源,并使得模型能够在单个服务器节点内运行。
Llama 3.1 405B 还有一些值得发掘的细节,比如其在设计上注重实用性和安全性,使其能够更好地理解和执行用户的指令。
通过监督微调、拒绝采样和直接偏好优化等方法,在预训练模型基础上进行多轮对齐,构建聊天模型,Llama 3.1 405B 也能够更精确地适应特定的使用场景和用户需求,提高实际应用的表现。
值得一提的是,Llama 研究团队使用合成数据生成来产生绝大多数 SFT 示例,这意味着他们不是依赖真实世界的数据,而是通过算法生成的数据来训练模型。
此外,研究团队团队通过多次迭代过程,不断改进合成数据的质量。为了确保合成数据的高质量,研究团队采用了多种数据处理技术进行数据过滤和优化。
通过这些技术,团队能够扩展微调数据量,使其不仅适用于单一功能,而是可以跨多个功能使用,增加了模型的适用性和灵活性。
简单来说,这种合成数据的生成和处理技术的应用,其作用在于创建大量高质量的训练数据,从而有助于提升模型的泛化能力和准确性。
作为开源模型路线的拥趸,Meta 也在 Llama 模型的「配套设施」上给足了诚意。
- Llama 模型作为 AI 系统的一部分,支持协调多个组件,包括调用外部工具。
- 发布参考系统和开源示例应用程序,鼓励社区参与和合作,定义组件接口。
- 通过「Llama Stack」标准化接口,促进工具链组件和智能体应用程序的互操作性。
- 模型发布后,所有高级功能对开发者开放,包括合成数据生成等高级工作流。
- Llama 3.1 405B 内置工具大礼包,包含关键项目,简化从开发到部署的流程。
值得注意的是,新开源协议里,Meta 不再禁止用 Llama 3 来改进其他模型了,这其中也包括最强的 Llama 3.1 405B,真·开源大善人。
附上 92 页论文训练报告地址:
https://ai.meta.com/research/publications/the-llama-3-herd-of-models/
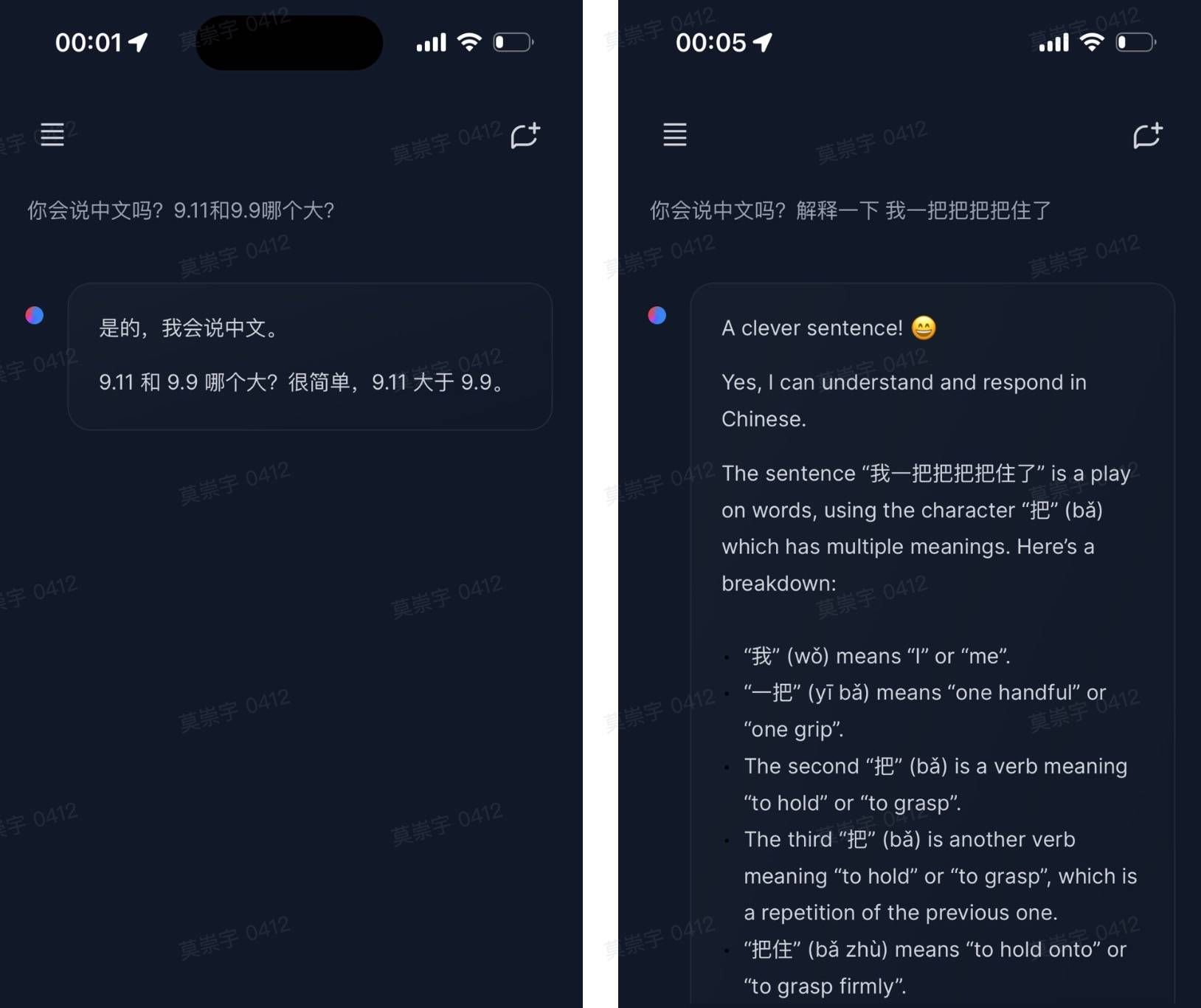
一个由开源引领的新时代网友 @ZHOZHO672070 也火速在 Hugging Chat 上测试了一下 Llama 3.1 405B Instruct FP8 对两个经典问题的回答情况。
遗憾的的是, Llama 3.1 405B 在解决「9.11 和 9.9 谁更大」的难题上遭遇翻车,不过再次尝试之下,又给出了正确答案。而在「我一把把把住了」的拼音标注上,其表现也尚可。
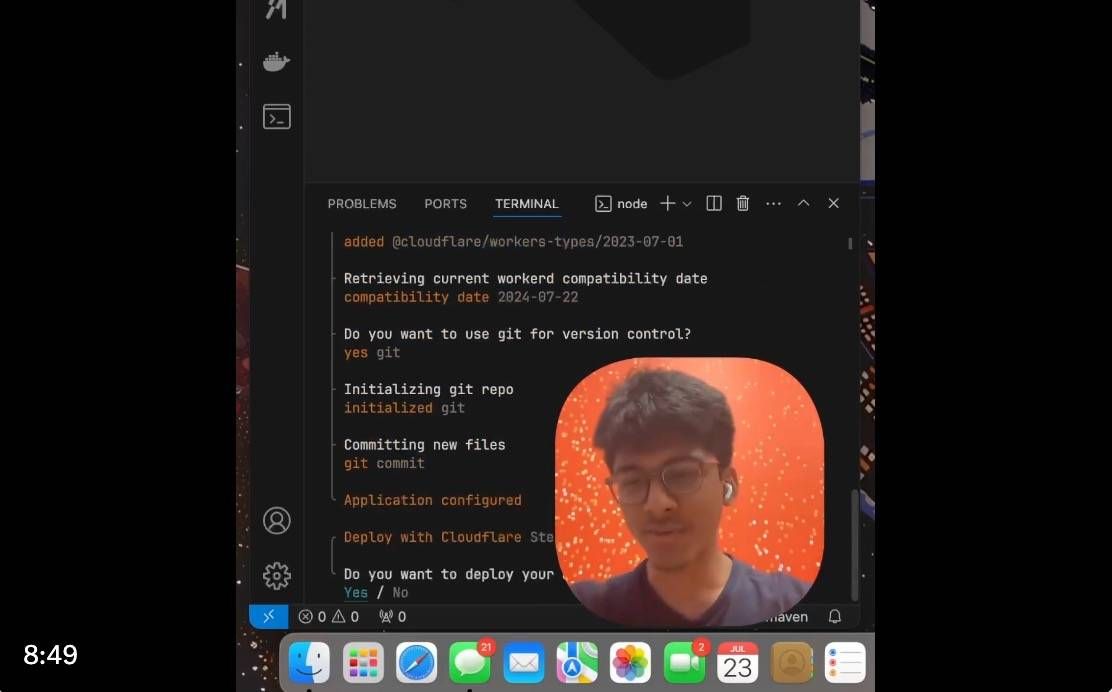
网友更是只用了不到 10 分钟的时间,就使用 Llama 3.1 模型快速构建和部署了一个聊天机器人。
另外,Llama 内部科学家 @astonzhangAZ 也在 X 上透露,其研究团队目前正在考虑将图像、视频和语音功能集成到 Llama 3 之中。
开源和闭源之争,在大模型时代依然延续着,但今天 Meta Llama 3.1 新模型的发布为这场辩论画上了句号。
Meta 官方表示,「到目前为止,开源大型语言模型在功能和性能方面大多落后于封闭式模型。现在,我们正迎来一个由开源引领的新时代。」
Meta Llama 3.1 405B 的诞生证明了一件事情,模型的能力不在于开或闭,而是在于资源的投入、在于背后的人和团队等等,Meta 选择开源或许出于很多因素,但总会有人扛起这面大旗。
而作为第一个吃螃蟹的巨头,Meta 也因此收获了首个超越最强闭源大模型的 SOTA 称号。

Meta CEO 扎克伯格在今天发布的长文《Open Source AI Is the Path Forward》中写道:
「从明年开始,我们预计未来的 Llama 将成为业内最先进的。但在此之前,Llama 已经在开源性、可修改性和成本效率方面领先。」
开源 AI 模型或许也志不在超越闭源,或出于技术平权,不会让其成为少数人牟利的手段,或出于众人拾柴火焰高,推动 AI 生态的繁荣发展。
正如扎克伯格在其长文末尾所描述的愿景那样:
我相信 Llama 3.1 版本将成为行业的一个转折点,大多数开发人员将开始转向主要使用开源技术,我期待这一趋势从现在开始持续发展……共同致力于将 AI 的福祉带给全球的每一个人。
#欢迎关注爱范儿官方微信公众号:爱范儿(微信号:ifanr),更多精彩内容第一时间为您奉上。
爱范儿|原文链接· ·新浪微博
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com