
作者 | GenAICon 2024
2024中国生成式AI大会于4月18-19日在北京举行,在大会第一天的主会场大模型专场,李未可科技合伙人兼AI负责人古鉴以《WAKE-AI打造室外AI硬件交互新路径》为题发表演讲。
李未可科技一直在摸索AI适合什么样的室外场景。古鉴分享说,相比手机和新型硬件,智能眼镜是更适合AI的载体,它能带来极致的轻薄,更适合室外场景的AI落地。大模型至少会为XR及AI眼镜等带来三方面的提升,包括交互更自然、陪伴更人性化、服务更精准。
古鉴在会上正式宣布,李未可科技发布针对“AI+终端”定向优化研发的多模态AI大模型平台WAKE-AI。WAKE-AI具备文本生成、语言理解、图像识别及视频生成等多模态交互能力,针对眼镜端用户的使用方式、场景等进行了优化。
古鉴认为在语音层面上,大模型整体反馈速度技能指令小于500毫秒,大模型层面小于2秒,这样用户才会觉得这个反馈是足够快的,而且它的反馈足够及时,才能够为用户提供户外运动、文化旅行、日程管理及实时翻译等多种多模态AI服务。古鉴还透露道,李未可科技的WAKE-AI就是以此为优化方向,并即将推出搭载WAKE-AI的终端新品。
以下为古鉴的演讲实录:
我今天主要跟大家分享《WAKE-AI打造室外AI硬件交互新路径》。李未可公司是2021年成立的,我们主要专注于以AR等眼镜形态的硬件为基础的AI研究以及产品,我本身也从事AI算法和AR算法大概超过十年。
一、智能眼镜是室外AI最适合的载体:轻薄、极致、续航长
首先跟大家分享一下,随着AI的爆发和发展,大家都在寻找AI的落地场景,什么样的落地场景最适合AI?比如有AI+Car、AI+PC,但是在室外什么样的场景最合适?我们一直在摸索。
AI在室外首先要轻、薄,要能随时交互,要方便,要看得清楚,这些都是AI对硬件的要求。我们在这方面做了很多调研,发现可能有三种方式在室外可以用作AI的主要交互方式。
第一种,手机。手机的接收方式是大家普遍可以接受的,每个人都有。但是它在某种程度上不是为AI设计的,所以在外面需要打开手机,需要拍照,需要打开语音助手跟它聊天,这不是一种很方便的交互方式。
第二种,最近比如Ai Pin,针对AI设计的硬件研发出来,我们发现这种硬件在用户接受程度上有一定挑战。毕竟是一个价格不菲新增的品类,目前从海外第一批用户的体验反馈来看,Ai Pin也是偏过渡的形式。
聚焦在硬件产品以后,我们发现以眼镜为基础的形态,其实既能被用户接受,又有广泛的使用场景。将眼镜戴在脸上,用户跟它沟通交流很方便。而且从传统的眼镜到智能眼镜,到AI眼镜,就是一个逐渐过渡的过程。

我们认为,智能眼镜是AI最适合的载体,尤其室外。我们做了很长时间的眼镜,从现在的趋势来看,以眼镜为基础分两条路线。
第一条路偏向室内场景,以办公、游戏等为主,要求沉浸的体验、极致的MR(混合现实)感觉。比如苹果Vision Pro很重,不适合带到室外,但是它的体验非常极致。
另一条路线偏向室外,比如本地生活、出行、旅游,这类场景下(用户)对AI眼镜的要求主要是信息的显示,你能实时交互、导航,能够听一些讲解,听音乐,而且有些蓝牙交互,这是我们定义信息屏的显示。AI的爆发,更加推动了这种形态眼镜的生长。
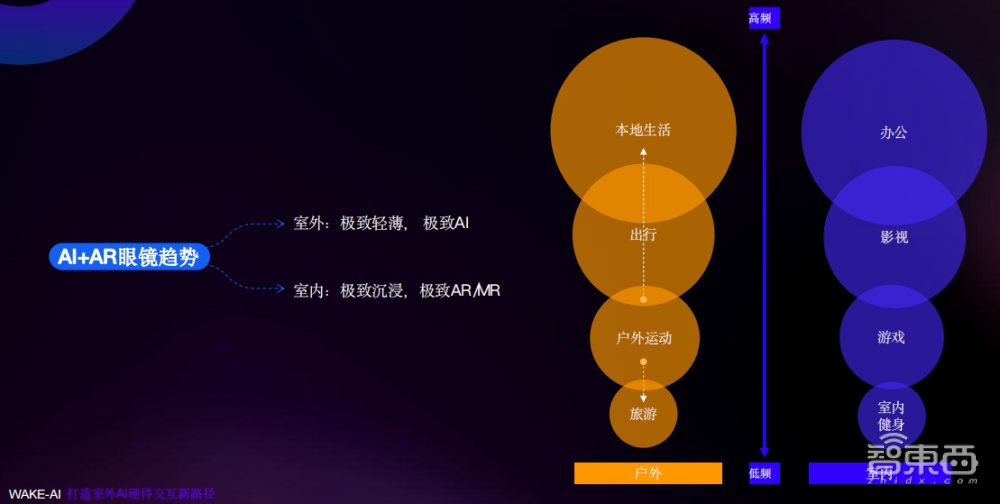
我们定义为室外要极致的轻薄、极致的AI,而且续航时间要足够长。室内要极致的沉浸,极致的AR、MR的感觉。
我们在去年发布了一款眼镜Meta Lens S3,这是一款针对室外场景发布的一款尝试性AR眼镜,具有语音交互功能,包括室外拍照功能、室外录像、蓝牙语音接电话、使用光波导双目显示等。这款眼镜已经售卖给消费者,取得了非常好的评价。
疫情结束以后,旅游场景有一个很大的爆发,很多年轻人喜欢出游,Citywalk(城市漫步)成为新的生活方式。我们有硬件基础,随着AI能力的爆发增长,我们能把硬件体验提升到非常好的程度;再加上我们的室外垂直场景,这对于我们来说,包括很多生态来说,都是非常好的机遇。
二、AI带来智能眼镜三大提升:更自然的交互、更人性化的陪伴、更精准的服务
AI到底能给我们的硬件,包括我们的用户交互体验带来哪些提升?
我认为有三个部分:第一,给我们带来更自然的交互;第二,有更人性化的陪伴;第三,在精准度和信息数量上能够提供更好的服务。
我们通过三种方式,能够不断地提升AI效果。
第一,我们使用定向优化的分发大模型,帮助快速地分发用户的指令,比如我要听歌,我要跟语音助手聊一聊。
第二,情感大模型,在人和冰冷的机器之间,我们需要有一份情感,有这份信任以后,用户才能够深深地信任这个硬件,才能让它去执行很多任务,才能把邮件系统开放给助手,让它理解邮件。
第三,针对室外场景需要大量的数据,包括使用多模态的VQA(视觉问答)模型,让用户可以指哪问哪,通过图片的方式得到相对应的信息,这也是我们重要的创新。
三、通过定向优化的分发大模型,满足更自然的交互
要满足更自然的交互,AI硬件首先需要什么样的特点?
首先,用户在眼镜上对回答的容忍度比在手机上容忍度低。我测试了很多语音大模型在手机上的反馈,包括豆包、海螺问问等,它的反馈时间都在5秒左右,我觉得这个反馈时间其实在眼镜上面无法接受。
我们认为在语音层面上,大模型整体反馈速度技能指令小于500毫秒,大模型层面小于3秒,这样用户才会觉得这个反馈是足够快的,而且它的反馈足够及时,才能解决用户的问题。
第二,室外场景的噪音比较多。我们定位室外场景,噪音场景很多,包括多人对话、汽车、骑车的声音。我们认为3A算法,比如回声消除、主动降噪、自动增益、通话降噪可能都是AI硬件需要满足的。在-5db情况下语音准确度大于90%,才能满足AI交互的基本需求,-10db的情况下(语音准确度要)大于85%。
另外,收音和ASR(自动语音识别)的效果需要保证。很多语音类的对话机器人其实ASR的效果都不是特别好,但是大模型的效果很好,把很多问题纠正了。
我认为ASR涉及很多的指令,ASR的字错率要低于2%,字准率大于98%,这些标准跟在VR行业内整体渲染速度要在20毫秒以内的标准类似。我认为这是一个室外AI硬件的基础标准。
在大模型还没有爆发之前,我们使用传统的算法时会面临很多解决不了的问题。
比如表达“我吃饭了,我要运动”,用户会加入很多自己的语言,但是他的意图可能是最后我要运动,怎么把这些泛化的问题解决,这些是难点之一;第二,“帮我打开导航,我要运动”,用户是想要导航还是想要运动,这本身就是涉及多意图的理解;第三,实现Agent(智能体)的能力,怎么调用App、调用Agent解决用户对应的意图;第四,多轮聊天的能力,上下文的指代消解,传统方法做得非常不好;另外,知识储备的有限,一些无法回答等。
这些都是大模型的优势。我们希望使用大模型的快速分发能力,包括使用轻量级模型,快速给用户一个反馈,能够达到很好的分发用户意图的效果。另外,大模型能支持AI Agent的能力,快速执行用户的买票、导航等意图。我们希望基于大模型回答用户高质量的问题,包括使用RAG(检索增强生成)进行搜索、判断等,这些都是分发大模型需要具备的。

基于AI眼镜的设计思路,其中包含了Memory模块、分发大模型模块。分发大模型主要通过语音输入来快速分发,比如聊天、信息搜索或指令,比如“我要听歌”或者“声音大一点”,通过这些分配来反馈到情感大模型的结果里。待会儿我会提到情感大模型和我们的Memory模块。在情感大模型里,我们会融入角色的设置,让用户的反馈会更加地拟真。
另外,我们有一个单独的Agent模块执行用户的指令,比如导航、买票、备忘录,这些可能都是用户的刚需。这是整体设计的框架,慢慢地,我们要转入如何让用户和机器建立情感的连接。
四、通过情感大模型及长记忆,提供更好的陪伴
我很喜欢的一部电影《她》(Her)。当这个人启动OS1系统的时候,他的第一感觉是,为什么这个跟人一样的声音是从机器里发出来的?这种情感连接在第一时间就快速地建立起来。我认为AI硬件尤其要跟人产生关联的时候,首先要考虑到的就是情感连接,比如它必须得像人,它能够知道喜好,能跟用户有深度的聊天。
我在很多对话机器人上聊差不多10轮到15轮以后,聊得非常尴尬,很多问题会聊不下去。如何进行有深度的聊天?包括角色的概念和不同Agent解决对应的问题,其中很重要的对《她》这部片子的感觉,AI助手一直在帮男人解决交流的问题,一直在帮他想各种各样的办法。这其实就是最后AI要帮助人交互、要解决的问题。
我们要有拟人化的DTS(数字化影院系统音频技术),要有长记忆的系统,要预训练一些知识,比如历史的信息、人物性格的定义,还有一些情感类Agent的调用,这些都是我们正在做和我们将要做的一些东西。
重点跟大家谈一下长记忆的这套系统。我跟我们的对话机器人聊的一段,其中有两块比较值得关注,一是根据之前我跟它聊天它得到的信息,它能知道我喜欢什么样的咖啡豆;二是它能够把它的知识库里大量的小众数据,融入到它的对话系统里,给我一个惊艳的反馈。
这就是我们期望用户能够天天使用AI眼镜的核心基础,通过核心记忆和长期记忆,不断更新用户的画像。
核心记忆主要用于不断得到用户的年龄、喜好等信息。长期记忆是把用户的很多信息进行构建索引后,最终存到长期记忆库里面,在长期记忆库里不断检索,最终汇总到核心记忆,到补充记忆信息的Prompt(提示词)里面。这样在每次对话中,系统就可以理解用户想要什么,还有一些记住的事情,慢慢地情感就会建立起来。
五、Citywalk户外多模态大模型,打造更精准的服务
第三部分,使用我们的眼镜去做Citywalk,这是年轻人尤其喜欢的一个室外项目。很多年轻人戴着我们的眼镜,尤其喜欢去拍第一视角视频,包括AI语音可以支持用户询问周边的信息。
我们跟杭州的学研机构联合研发了一条路线,以孤山为基础,在这条路线上,有很多小朋友戴着眼镜沿着不同的景点,去询问,学到很多知识。这条路线受到学研机构的大力推广和很多小朋友的喜爱,现在依然在运营,有兴趣体验的人可以联系我们去孤山体验。
我们的“旅游助手+城市漫游系统”,核心是数据内容,以景区作为核心供给,现在大概有2000多个景区数据。另外,我们从小红书、去哪儿网获取了小众的特色地点和路线,还有当地人会去的一些美食餐厅,通过人工和半自动的方式来吸收这些数据,不断整理,形成我们的路线、推荐、游览攻略。
最终给到用户的核心体验,一是景点游览,用户在景区可以问比如“岳王庙的历史”等问题;还有自动巡航系统,使用到VQA系统,当用户问“岳王庙里的碑写的到底是什么”,可以用手指点去询问,这也用到了多模态+LBS的系统;三是地点弹幕,用户根据LBS的地点信息,可以留言、发布一些相关到此一游的相关信息,你的朋友看到了可能会联系你。
多模态大模型可以做到“指哪儿问哪儿”,小朋友非常喜欢这样的体验。整体使用多模态+GPS跨模态向量的系统,最终使用了多模态大语言模型生成了相对应的内容。
之前我们也做过很多跟SLAM(同时定位与地图构建)相关的技术,通过用户第一视角的视频先用SLAM生成相对应的视频,再通过视频生成的方式,让用户觉得在骑行或者走路过程中整体第一视角的视频非常酷炫,这也是眼镜里提供的视频后处理中很有特色的功能。
再加上我们可以通过游记的方式进行生成,当游览完整个路线以后,你可以自动生成路线,可以通过这个路线把视频、图片、游记快速分享出来,这是整个旅游的一套行程系统。
六、发布多模态大模型平台WAKE-AI,共建室外AI+AR眼镜生态
这是WAKE-AI整体大模型的框架,我们希望把这个框架分享给大家,跟大家一起来建设AR眼镜+AI能力、在室外等多个场景的生态。

我们把WAKE-AI整套系统输入到李未可App的开发平台,用户可使用自定义的编排逻辑,包括可以通过我们的平台编辑你想在眼镜上显示什么样的位置等信息,同时发布到李未可的“AI Store”上,通过终端眼镜显示出来。
我们希望和大家一起去共建这个生态,也希望逐步开放出很多算法能力,这样才能够一起把AI真正落地。李未可AI平台也开放了特邀群,大家感兴趣的话可以加入进来,我们一起探讨,逐步释放我们的能力。
同时,我们也在4月底正式发布李未可AI眼镜,很多功能可以在这款眼镜上体现出来。售价定为699元,非常友好的价格,让大家去体验新一代的AI交互。
以上是古鉴演讲内容的完整整理。
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com