梦晨 发自 凹非寺
量子位 | 公众号 QbitAIAI伪造真人视频,门槛再次降低。
微软发布一张图生成数字人技术VASA-1,网友看过直呼“炸裂级效果”,比“AI刘强东还真”。

话不多说,直接上一分钟演示视频:
做到以假乱真效果,不用针对特定人物训练,只要上传一张人脸图片、一段音频,哪怕不是真人也行。
比如可以让蒙娜丽莎唱Rap,模仿安妮海瑟薇即兴吐槽狗仔队名场面。
或者让素描人像念华强台词。
在项目主页还有更多1分钟视频,以及更更多15秒视频可看。
不同性别、年龄、种族的数字人,用着不同的口音在说话。

根据团队在论文中的描述,VASA-1拥有如下特点:
- 唇形与语音的精准同步
这是最基本的,VASA-1在定量评估中也做到了顶尖水平。
- 丰富而自然的面部表情
不光做到让照片“开口说话”,眉毛、眼神、微表情等也跟着协调运动,避免显得呆板。
- 人性化的头部动作
说话时适当的点头、摇头、歪头等动作,能让人物看起来更加鲜活、更有说服力。
总得来说,仔细看的话眼睛还有一些破绽,但已经被网友评为“迄今为止最佳演示”。
然而更恐怖的是,整个系统推理速度还是实时级的。
生成512x512分辨率的视频,使用一块英伟达RTX4090显卡就能跑到40fps。
那么,VASA-1是如何做到这些的呢?
3大关键技术,Sora同款思路
一句话概括:
不是直接生成视频帧,而是在潜空间中生成动作编码,再还原成视频。
是不是和Sora的思路很像了?
其实VASA-1的模型架构选择Diffusion Transformer,也与Sora核心组件一致。

据论文描述,背后还有3大关键技术:
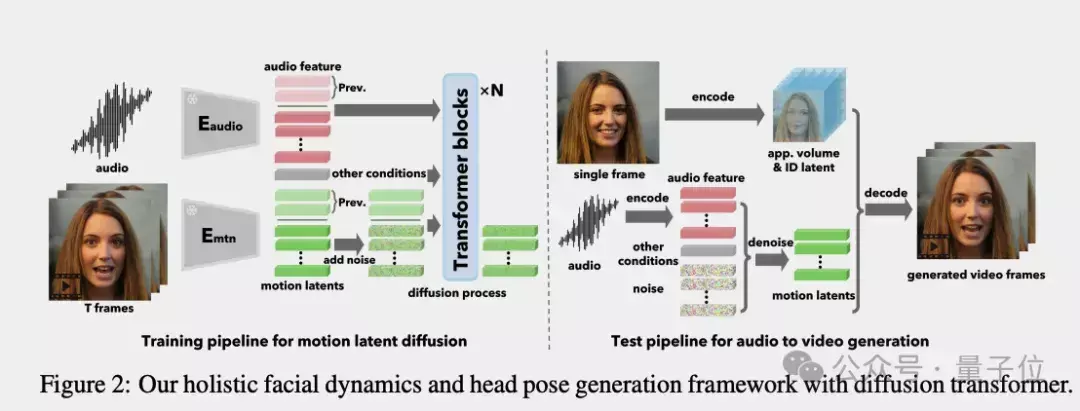
人脸潜编码学习,这部分是高度解耦的。
团队从大量个真实的说话视频中,学习到一个理想的人脸特征空间。
把身份、外观、表情、姿态等因素在隐空间里剥离开。这样一来,同一个动作就能驱动不同的脸,换成谁都很自然。

头部运动生成模型,这部分又是高度统一的。
不同于之前的方法分别建模嘴唇、眼神、眉毛、头部姿态等局部动作,VASA-1把所有面部动态统一编码,用Diffution Transfromer模型,也就是SORA同款核心组件,来建模其概率分布。
这样既能生成更协调自然的整体动作,又能借助transformer强大的时序建模能力,学习长时依赖。
比如给定一组原始序列(下图第一列),最终可以做到:
- 用原始头部姿态,改变面部表情(第二列)
- 用原始面部表情,改变头部姿态(第三列)
- 用原始面部表情,生成全新的头部姿态(第四列)

最后是高效率推理。
为了实现秒实时合成,团队对扩散模型的推理过程进行了大量优化。
此外,VASA-1还允许用户输入一些可选的控制信号,比如人物的视线方向、情绪基调等,进一步提升了可控性。

AI造假成本越来越低了
被VASA-1效果震惊过后,很多人开始思考,把AI数字人做到如此逼真,发布这样一个技术真的合适吗?


毕竟用AI伪造音频视频诈骗的例子,我们已经见过太多。
就在2个多月前,还有一起假冒公司CFO开视频会议,直接骗走1.8个亿的案件发生。
微软团队也意识到了这一问题,并作出如下声明:
我们的研究重点是为数字人生成视觉情感,旨在实现积极的应用。无意创建用于误导或欺骗的内容。
然而,与其他相关内容生成技术一样,它仍然可能被滥用于模仿人类。
我们反对任何创造真实人物的误导性或有害内容的行为,并且有兴趣应用我们的技术来推进伪造检测……
目前VASA-1只发布了论文,看来短时间内也不会发布Demo或开源代码了。
微软表示,该方法生成的视频仍然包含可识别的痕迹,数值分析表明,距离真实视频的真实性仍有差距。
不上专业评估手段,肉眼看的话,仔细挑刺或直接对比真人视频,确实也能发现目前VASA-1演示视频中的一些瑕疵。
比如牙齿偶尔会变形。

以及眼神还不像真人那么丰富。(眼睛确实是心灵的窗户啊)
但是以“AIGC一天,人间一年”的进步速度来看,修复这些瑕疵恐怕也不用很久。
以及你能保证每时每刻都保持警惕分辨视频真假么?
眼见不再为实。默认不相信任何视频,成了很多人今天做出的选择。
不管怎么样,正如一位网友总结。
我们无法撤销已经完成的发明,只能拥抱未来。
论文地址:https://arxiv.org/abs/2404.10667
参考链接:[1]https://www.microsoft.com/en-us/research/project/vasa-1/[2]https://x.com/bindureddy/status/1780737428715950460
— 完 —
量子位 QbitAI · 头条号签约
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com