
友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
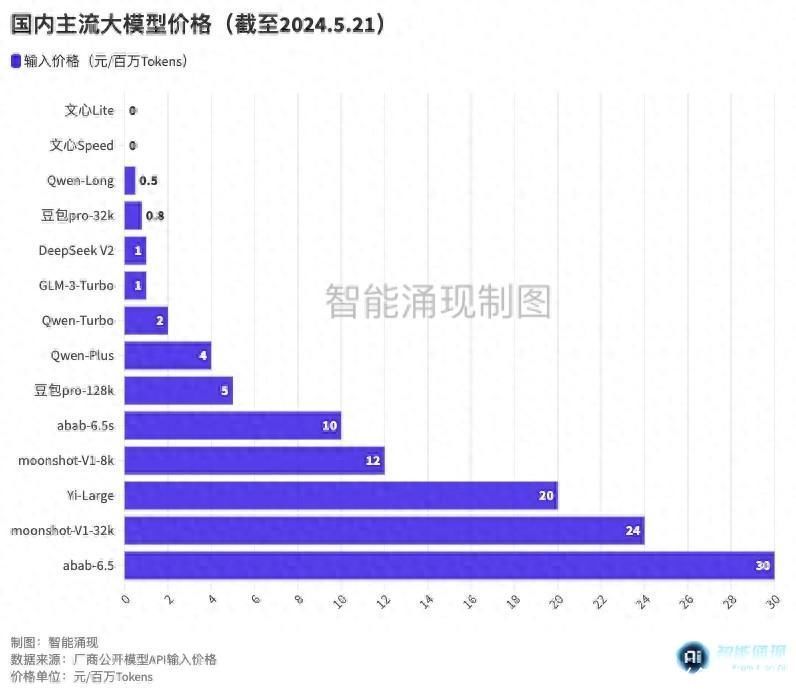
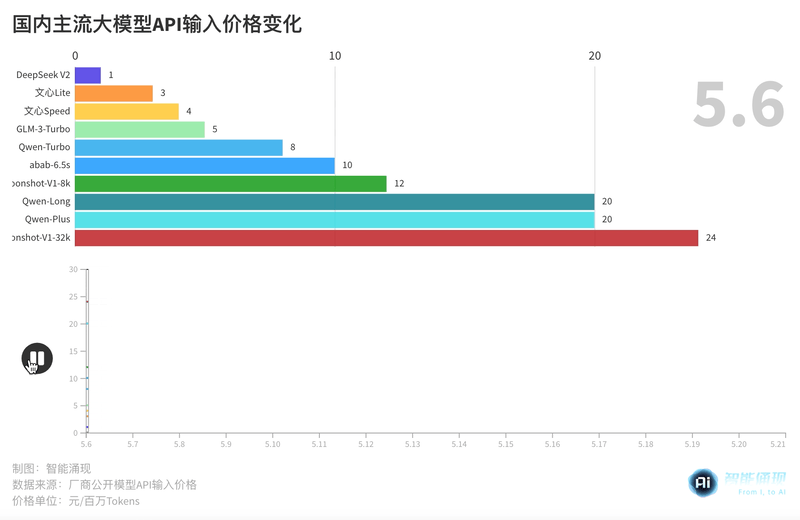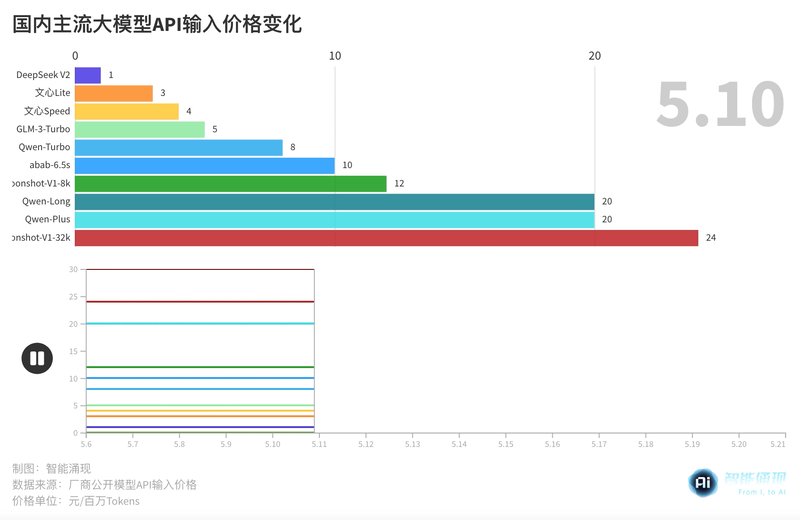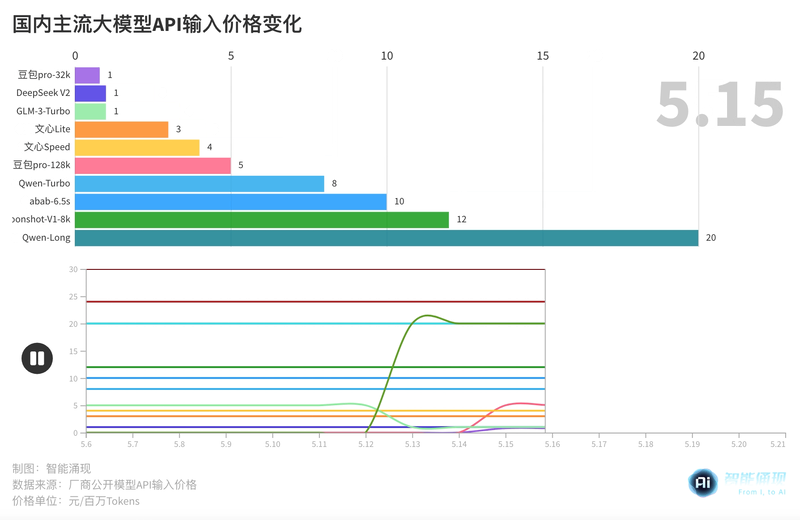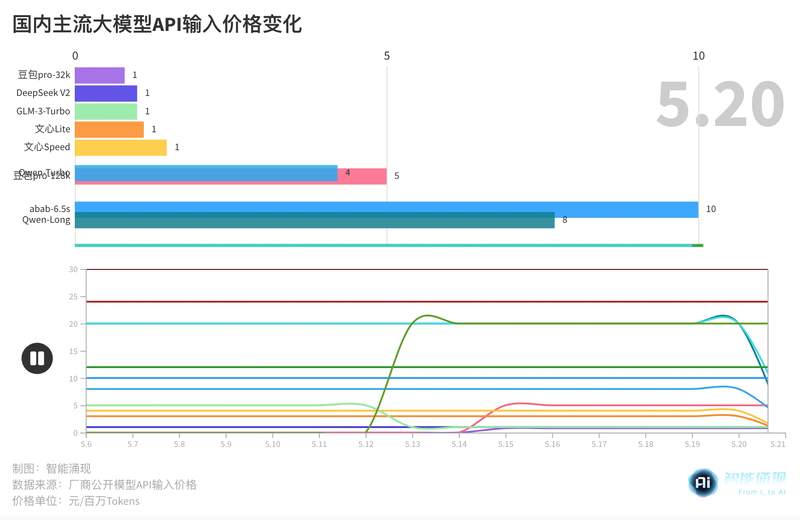
大模型“618”开启,阿里:我降价!百度:我免费!| 最前线
46
0
相关文章
近七日浏览最多
最新文章
标签云
阿里云
优酷
云计算
北京
奥运
蔡崇信
人工智能
奥运会
商汤
中国国家队
亚马逊
东京奥运
中国
美国
天眼查
卫星
奥林匹克
巴黎
东京奥运会
中国队
黄宗治
平行宇宙
直播
北京冬奥会
元气满满
动力电池
商务部
蔚来
阿里
白皮书
腾讯云
乒乓球
阿里巴巴集团
esg
天猫
ipad
网易
安卓
ios
时代周报
gpu
影视
网剧
边水往事
制片人
上海电视节
三边坡工作室
三边坡
贝鲁特
黎巴嫩
真主党
以军
ds
刘强东
京东集团
拼多多
世界500强
京东
腾讯
华中科技大学
华为
毕业生
韩愈
融资
初创公司
健美
腹肌
健身
肌肉
拉斐尔
锻炼
app
里根
高盛
招商证券
龙王
王者归来
泰森
恒生指数
中国重汽
新华保险
福耀玻璃
新东方
小米
香港联交所
申万宏源
港元
达摩院
ibm
云南
尼泊尔
斯里兰卡
昆明
turbo
imax
酷狗音乐
北大
韦神
北京大学
小红书
ipo