友情提示
本站部分转载文章,皆来自互联网,仅供参考及分享,并不用于任何商业用途;版权归原作者所有,如涉及作品内容、版权和其他问题,请与本网联系,我们将在第一时间删除内容!
联系邮箱:1042463605@qq.com
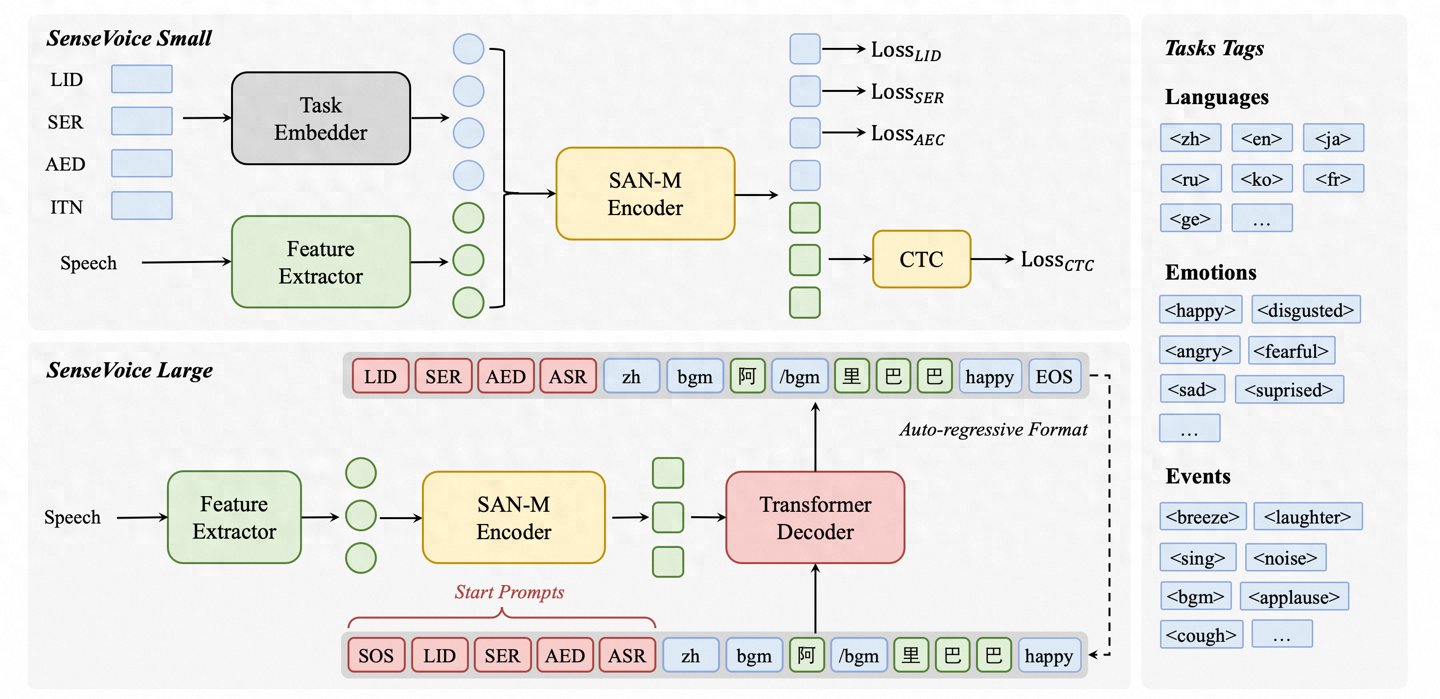
阿里云通义SenseVoice与CosyVoice两款语音基座模型正式开源
10
0
相关文章
近七日浏览最多
标签云
语音识别
家居
天猫
音箱
速腾
无框车门
液晶仪表
用车成本
上汽大众
大众凌渡
大众
牛米
轿跑suv
大众汽车
新能源车
cvt
轩逸
hr16
日产
ev
置换补贴
混动系统
凯美瑞
丰田
新能源汽车
at变速箱
三缸机
国产车
国产品牌
海豚
运动模式
无线充电
凯迪拉克
比亚迪秦
日产轩逸
阿里云
科大讯飞
交通银行
gpu
小米
siri
显卡
中国电信
人脸识别
人工智能技术
特斯拉
马斯克
机器人
特斯拉公司
世界首富
你的名字
上海交大
pilot
ipad
ios
苹果
聊天记录
搜索引擎
人工智能
动力总成
皓影
honda
SUV
无级变速
电动尾门
英伟达
pdf
mega
mpv
oled
android
学习习惯
优酷
云计算
北京
奥运
蔡崇信
奥运会
商汤
中国国家队
亚马逊
东京奥运
中国
美国
天眼查
卫星
奥林匹克
巴黎
东京奥运会
中国队
黄宗治
平行宇宙
直播
北京冬奥会
元气满满
动力电池
商务部
蔚来
阿里
白皮书
腾讯云
乒乓球
阿里巴巴集团
esg
网易
安卓
时代周报